

All-in-One Reliability Platform
The All-in-One Reliability Stack for Modern Teams
upti.my combines uptime monitoring, cron job monitoring, synthetic checks, incident management, status pages, alerting workflows, and self-healing agents in one platform.
No credit card required · 14-day free trial · Cancel anytime
Up and running in minutes
Add what you want to watch
~2 minHTTP endpoints, cron jobs, user journeys, SSL certs, TCP ports, DNS, gRPC, GraphQL, or Ping checks.
Route alerts & automate response
no-codeDrag and Drop workflows send alerts to Slack, Discord, Teams, Webhooks, Email, or all of them at once. Set escalation rules, maintenance windows, and smart deduplication.
upti.my detects, alerts & recovers
<30sAgents auto-restart failing services. Your status page updates automatically. Incidents are tracked, and customers stay informed without you lifting a finger.
From €9/mo
After free trial
99.99%
Platform uptime
Platform Uptime
Alert Delivery Time
Minimum Check Interval
Global Monitoring Regions
Everything in one reliability stack
Six capabilities. One platform. No duct tape.
- HTTP, TCP, DNS, SSL, Ping, GraphQL, gRPC
- Request breakdown timing per phase
- Checks as fast as every 10 seconds
- Detect missed, delayed, and failed jobs
- Configurable grace periods
- Simple ping-based integration
- Playwright-powered multi-step scenarios
- Login, signup, checkout flow testing
- Screenshot on failure for fast debugging
- Automatic status page updates on incidents
- Maintenance windows and scheduling
- Full incident timelines for post-mortems
- Public and private status pages
- Custom domains with SSL, white-label branding
- Embeddable status widgets
- Alert routing, escalation, and deduplication
- Automatic service restart on failure
- Custom recovery scripts
One reliability stack instead of five separate tools
Most teams stitch together uptime monitoring, cron monitoring, status pages, incident management, and alert routing from different vendors. upti.my replaces all of them.
Before: 5+ separate tools
- ✕Uptime monitoring tool
HTTP checks only, no recovery
- ✕Cron monitoring service
Separate vendor, separate billing
- ✕Status page provider
Manual updates, no auto-sync
- ✕Incident management tool
Disconnected from monitoring data
- ✕Alert routing / PagerDuty
Another subscription, another dashboard
Result: fragmented data, alert fatigue, context switching, higher cost
After: One platform
- Uptime monitoring
9 protocols, 15s checks, global regions
- Cron & heartbeat monitoring
Built in, same dashboard
- Status pages
Auto-synced with monitors, white-label ready
- Incident management
Connected to every check and alert
- Workflows & self-healing
Route alerts, automate recovery, zero context switch
Result: unified data, faster response, lower cost, one bill
One dashboard
Every signal in one place, no tab switching
One bill
Starting at €9/mo instead of €100+/mo across vendors
Connected data
Monitors, alerts, incidents, and status pages share context
Live in 2 minutes
First check live in minutes, not weeks of onboarding
Why Teams Choose upti.my
Built for teams who need reliability, not just monitoring
One stack, not five tools
Replace separate monitoring, alerting, status page, incident management, and cron monitoring vendors with one platform. One dashboard, one bill.
Faster detection and response
10-second checks, sub-30-second alert delivery, and automated recovery. Know about issues before your customers do.
Silent failure coverage
Cron jobs, background workers, and scheduled tasks that fail silently get caught. No more "it's been broken for three days."
Customer trust through transparency
Branded status pages and automated incident communication. Customers stay informed without you sending manual updates.
Automation and self-healing
Agents auto-restart failed services. Recovery scripts execute automatically. Reduce MTTR from hours to seconds.
Lower cost, less tool sprawl
Starting at €9/mo instead of €100+/mo across vendors. One integration point, shared context across every capability.
Built for teams that cannot afford silent failures
Whether you ship SaaS, run client infrastructure, or are scaling a startup, upti.my keeps your services reliable
Uptime is your product. Track SLAs, alert on API failures, show customers branded status pages, and keep your 99.9% promise.
- • SLA tracking and uptime reports
- • Public and private status pages
- • Incident management with auto-updates
- • Multi-region API monitoring
Full reliability stack from day one. No vendor sprawl, no over-engineering. Smart defaults, fast setup, affordable pricing.
- • Free 14-day trial, no credit card
- • Monitoring, alerts, status pages included
- • Scales with you as you grow
- • One tool instead of five
White-label status pages per client. Manage dozens of projects from one dashboard. Custom branding and domains included.
- • Per-client status pages and branding
- • Multi-project management
- • Custom domains with SSL
- • Volume-friendly pricing
Deep infrastructure monitoring with self-healing agents. Workflow-driven alert routing. Built for engineers, not managers.
- • Self-healing agents for critical services
- • Custom recovery scripts
- • Alert escalation and deduplication
- • Keyboard-first, command palette (⌘K)
All Systems Operational
All systems are running smoothly
Know the moment something breaks
Comprehensive monitoring for all your services with real-time status updates and beautiful status pages to keep your users informed.
- HTTP, HTTPS, TCP, DNS, SSL, gRPC, GraphQL, Ping
- Check frequencies from 15s to 1h (varies by plan)
- Response time and performance tracking
- Customizable status pages with your branding
Detect, alert, and recover automatically
Deploy agents that detect process failures and execute recovery procedures automatically. Self-healing is the advanced response layer that closes the loop after monitoring, alerting, and communicating.
- Process monitoring with automatic restart policies
- Framework-agnostic deployment (Docker, systemd, PM2)
- Configurable health checks and recovery scripts
- Real-time metrics and recovery event logging
Automate your incident response
Build alerting workflows with a drag-and-drop interface. Customize escalations and route alerts to the right teams at the right time.
- Drag-and-drop workflow builder with visual editor
- AI-powered issue identification (Premium)
- Smart escalation policies with time-based triggers
- Alert suppression and scheduling for maintenance
- Multiple destination routing (email, Slack, webhooks)
- Conditional logic and custom alert formatting
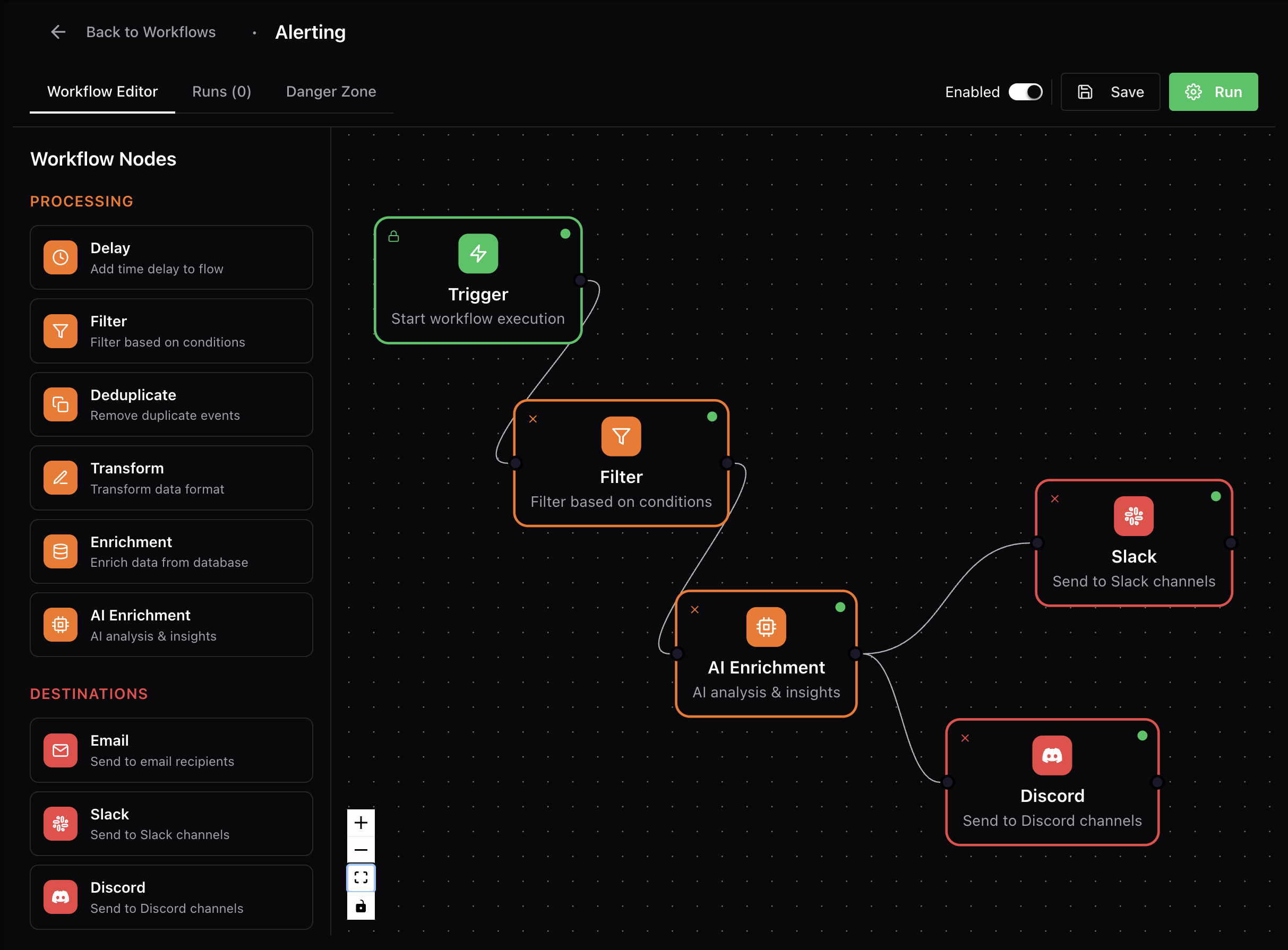
Available Integrations
Instant email alerts
Webhook
Custom HTTP callbacks
Slack
Channel notifications
Microsoft Teams
Enterprise workflows
Discord
Community notifications
PagerDuty
On-call escalation
SMS
Text message alerts
Mobile notifications
Coming soon: Telegram, Linear
Get notified the moment it matters
Smart alerting that cuts through the noise. Get instant notifications when issues occur, with intelligent policies that ensure you're alerted to what matters most.
- Multiple notification channels available
- Smart escalation policies and alert grouping
- Customizable alert conditions and thresholds
- Noise reduction with intelligent filtering
- Public status pages to keep users informed
Pricing
Choose the plan that fits your team. All plans include monitoring, alerting, incidents, and status pages.
- Unlimited private status pages
- Vendor-branded public page
- Incident management
- Basic alerting
- Unlimited team members
- Unlimited private status pages
- Incident management
- Advanced alerting
- Custom domain name
- White-label status page
- Unlimited team members
- Unlimited private status pages
- Unlimited incidents
- Advanced alerting
- SLA reporting
- Priority support
- Custom domain name
- White-label status page
- Unlimited team members
- SSO integration
- Custom SLAs
- Dedicated support
- Full white-label
- Custom domain name
- Unlimited team members
Frequently Asked Questions
Find answers to common questions about our platform.
The free trial gives you full access to the Starter plan for 14 days with no credit card required. This includes up to 10 services, 60-second check intervals, self-healing agents, branded status pages, and all Starter features. After the trial, you can choose to continue with Starter or upgrade.
Yes, you can upgrade or downgrade your plan at any time. When upgrading, you'll be charged the prorated amount for the remainder of your billing cycle. When downgrading, the new rate will apply at the start of your next billing cycle.
You can monitor HTTP/HTTPS endpoints, TCP ports, DNS records, SSL certificates, gRPC services, GraphQL APIs, and ICMP (Ping). upti.my also supports Playwright-based synthetic monitoring for user journey testing, and heartbeat monitoring for cron jobs and background workers.
Our agents are lightweight daemons that integrate with your process management layer (systemd, Docker, PM2, etc.). They continuously monitor application health through configurable checks and execute predefined recovery scripts when failures are detected. The agents operate independently without requiring external orchestration platforms.
upti.my replaces the combination of separate uptime monitoring tools, cron job monitoring services, status page providers, incident management tools, and alert routing platforms. Instead of stitching together 5+ vendors, you get one integrated platform with shared context across all capabilities.
Simply sign up for a free account, add your first health check, and you're ready to go. The onboarding process will guide you through setting up your first status page and configuring alerts. No credit card is required for the free trial.
Get in Touch
Have questions or need help? Our team is here to assist you.
Ready to keep your services reliable?
Set up your first check in minutes. Monitoring, alerts, incidents, and status pages from day one. No credit card required.